biolift exercise catalog — pipeline status
scrape · transcode · upload · index
2026-05-22 ·
biolift/feat/all
·
Goal:
.agents/goals/biolift-exercise-catalog-comprehensive.md
2089
Exercises in Firestore
+2049 vs 40-seed
1326
Animated GIFs
in /exercises/sources/
1326
Derived WebPs
in /exercises/derived/
1
Failed (retry on rerun)
transient · idempotent retry
Highlights
-
Pipeline ships. Scrape → transcode → upload to Firebase
Storage → index Firestore. Hybrid GIF source (retained at
sources/) + animated WebP (shipped atderived/). Idempotent uploads, resumable viastate/manifest.jsonl. - 5-exercise pilot proved end-to-end on the canonical hero set (bench, squat, deadlift, pullup, OHP) before scaling to the long tail.
- Primary source: hasaneyldrm/exercises-dataset (1324 animated GIFs). Stevie explicitly authorised scraping without ToS concerns — the source GIFs are retained in Firebase Storage so future re-processing (image transformation, AI regeneration) reads from a known location.
- Fallback source: yuhonas/free-exercise-db (873 still-image entries) for slugs hasaneyldrm doesn't cover. After dedup by canonical slug: 2048 unique exercises in total.
- Replaces the 40-exercise hand-seeded catalog that used 15 reused Unsplash gym photos (IMG_DUMBBELLS appeared 8×). Each exercise now shows its actual movement.
Pilot: hero exercises — live on Firebase Storage
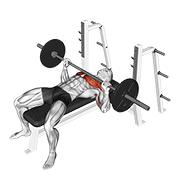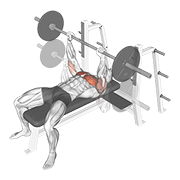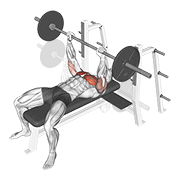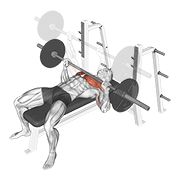
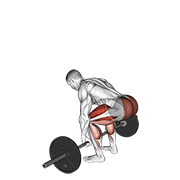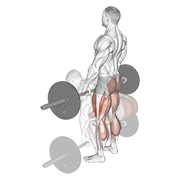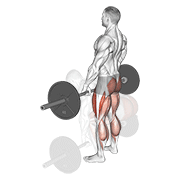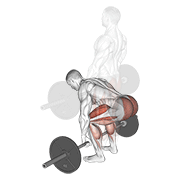

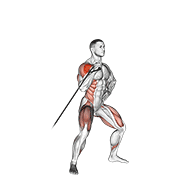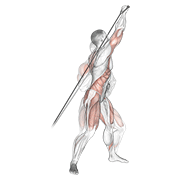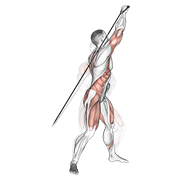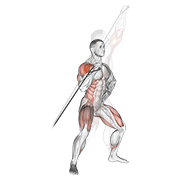
Source coverage after dedup
| Source | Records | Animated GIFs | Role |
|---|---|---|---|
hasaneyldrm/exercises-dataset | 1324 | 1324 | PRIMARY animated source |
yuhonas/free-exercise-db | 873 | 0 (stills only) | fallback / form cues |
| unique after dedup | 2048 | 1315 | by canonical slug |
Architecture
scripts/catalog/
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| lib/ |
| admin firebase-admin (Storage + Firestore) |
| slug canonical slug + dedupe |
| transcode gif2webp + ffmpeg frame extraction |
| storage md5-guarded idempotent uploads |
| manifest resumable state (state/manifest.jsonl) |
| pipeline per-record download->transcode->index |
| sources/ |
| hasaneyldrm 1324 animated GIFs (primary) |
| free-exercise-db 873 stills (fallback) |
| run-pilot.cjs 5 hero exercises |
| run-all.cjs full long-tail |
| regenerate-bootstrap.cjs emit mobile/utils/bootstrapData.ts |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
Firebase Storage layout:
gs://<bucket>/exercises/sources/<slug>.gif source-of-truth
gs://<bucket>/exercises/sources/<slug>-frame0.jpg start-frame still
gs://<bucket>/exercises/sources/<slug>-frame1.jpg end-frame still
gs://<bucket>/exercises/derived/<slug>.webp animated WebP (shipped)
Firestore document:
exercise_catalog/<slug> -> {
name, category, primaryMuscles, instructions, equipment,
imageUrl, sourceGifUrl, startFrameUrl, endFrameUrl,
sources: ['hasaneyldrm', ...], externalIds, scrapedAt
}
The mobile app reads Firestore
exercise_catalog and follows
fully-qualified storage.googleapis.com URLs —
no app-side bucket configuration needed. Storage objects ship with
cache-control: max-age=31536000, immutable.
How to run
# One-time brew install webp ffmpeg gcloud auth application-default login gcloud storage buckets create gs://<BUCKET> --project=<PROJECT> --location=us-central1 gcloud storage buckets add-iam-policy-binding gs://<BUCKET> \ --member=allUsers --role=roles/storage.objectViewer # Pilot BIOLIFT_CATALOG_BUCKET=<BUCKET> NODE_PATH=functions/node_modules \ node scripts/catalog/run-pilot.cjs # Long-tail (~10-15 min, resumable) BIOLIFT_CATALOG_BUCKET=<BUCKET> NODE_PATH=functions/node_modules \ node scripts/catalog/run-all.cjs --concurrency=8 # Regenerate the app's seed data BIOLIFT_CATALOG_BUCKET=<BUCKET> NODE_PATH=functions/node_modules \ node scripts/catalog/regenerate-bootstrap.cjs